项目发展历程
DZ-TiDPO
ACL 2026 Submission
Overcoming State Inertia: 针对长上下文对话中模型“固守历史、难以适应新指令”的问题,提出的一种最小侵入式对齐框架。
核心贡献包括:
• ⚡ Temporal Attention Bias: 在推理端引入时序注意力偏置。
• ⚖️ Dynamic KL Constraint: 训练端实现语义自适应的动态约束。
• 📉 SOTA 性能: 在 IC-Bench 及多轮对话任务上超越标准 DPO。
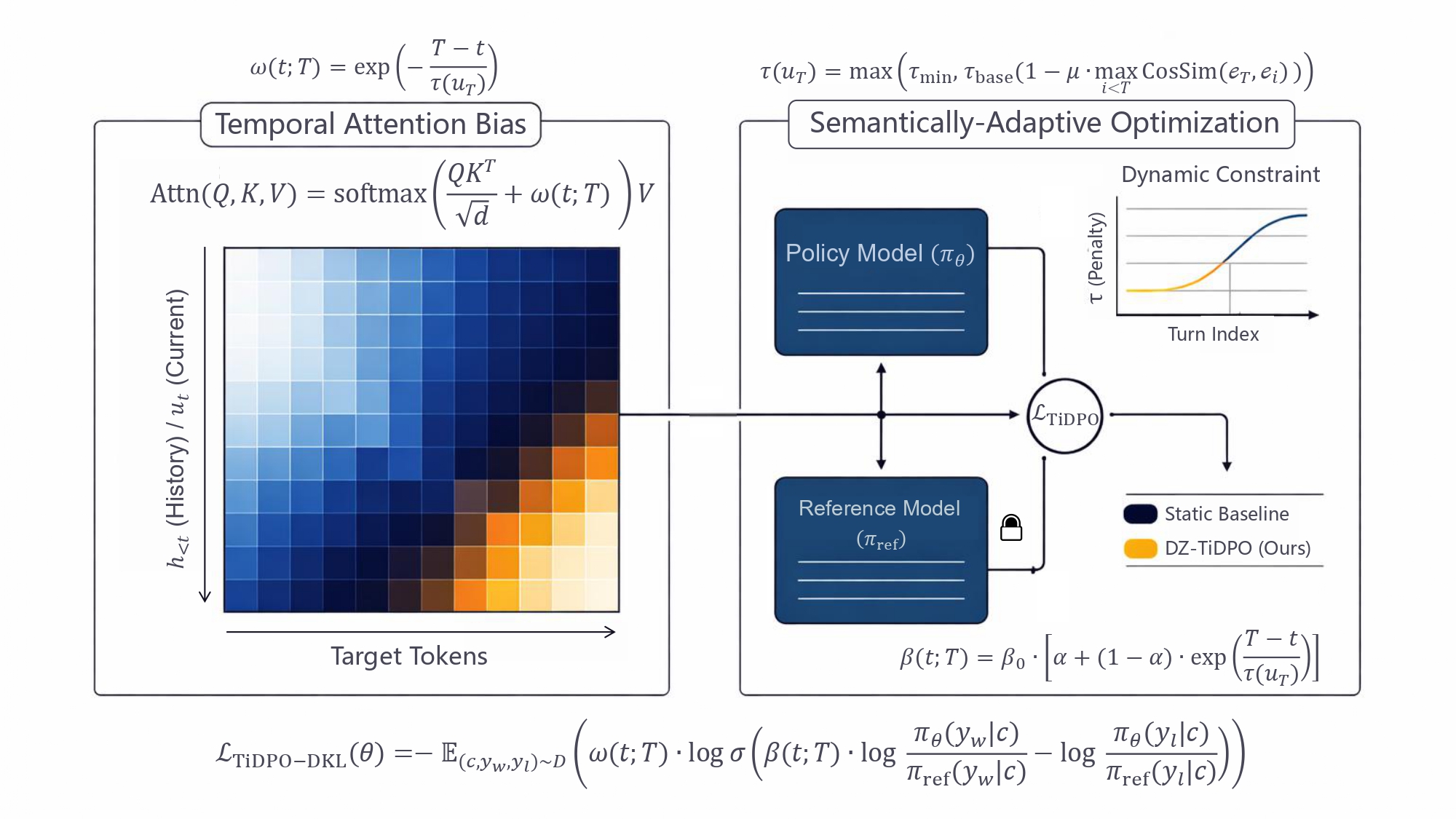
Figure 1: The DZ-TiDPO Framework Architecture
2025年7月~至今 - 技术突破
最新进展YingHub V3 - 稀疏混合专家语言模型
基于Triton实现Flash Attention,支持异构专家和动态Top-k路由的先进语言模型架构。 引入戏剧结构强化和流式数据迭代器,大幅提升模型性能和训练效率。
强化学习算法集 - 完整实现
完整的强化学习算法实现,包括DQN、PPO、DDPG、TD3等主流算法和ICM、RENT、RaR、INTUITOR等前沿算法。 支持多种环境训练或LLM,从经典控制到连续控制任务、从无监督到自监督的全面覆盖。
2025年及以前 - 基础积累
学习探索YingHub V2
混合专家Transformer架构
YingGem
滑动窗口注意力机制
CUDA矩阵乘法
GPU并行计算优化